![[レポート] Aurora をベクトルデータベースとして AI 駆動型の生成型検索を構築するワークショップ「Build generative AI–powered search with Amazon Aurora and Amazon RDS [REPEAT]」 #DAT301-R #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート] Aurora をベクトルデータベースとして AI 駆動型の生成型検索を構築するワークショップ「Build generative AI–powered search with Amazon Aurora and Amazon RDS [REPEAT]」 #DAT301-R #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
コーヒーが好きな emi です。
AWS re:Invent 2024 で Workshop 「Build generative AI–powered search with Amazon Aurora and Amazon RDS [REPEAT](Amazon Aurora と Amazon RDS で AI 駆動型の生成型検索を構築する)」に参加しました。
ちなみに [REPEAT] がついているのは re:Invent 期間中何回か開催されるセッションです。
このワークショップでは、Aurora PostgreSQL をベクトルデータベースとして設定し、Bedrock と統合することで、商品検索やレコメンデーションの精度を向上させる方法を学びました。商品説明をエンベディング(ベクトル)として保存し、セマンティック検索やパーソナライズされた提案を行うシステムを構築します。また、ナレッジベースやエージェントを活用して、動的な応答やデータ統合を可能にする仕組みを体験しました。
概要
タイトル:DAT301-R | Build generative AI–powered search with Amazon Aurora and Amazon RDS [REPEAT]
Amazon Aurora PostgreSQL互換エディションとAmazon RDS for PostgreSQLにLLMから生成された埋め込みを統合することで、商品カタログの類似検索体験を最適化する強力かつ効率的なソリューションが提供されます。基礎モデルとベクトル埋め込みを使用することで、企業はRetrieval Augmented Generation(RAG)を使用して類似性検索の精度と速度を向上させることができ、最終的にはユーザー満足度の向上とよりパーソナライズされた体験につながります。このワークショップでは、Aurora PostgreSQLをベクトルデータベースとして使用して、Amazon Bedrockで独自の生成AIアプリケーションを構築します。参加するには、ノートパソコンを持参する必要があります。
スピーカー
Shayon Sanyal(Principal WW SSA PostgreSQL, Amazon Web Services, Inc.)
Jonathan Katz
Principal Product Manager - Technical, AWS
Wed, December 4
3:30 PM - 5:30 PM PST
Venetian | Level 3 | Lido 3104
Session types: Workshop
Topic: AI/ML, Databases
Area of interest: Generative AI, Open Source
Level: 300 – Advanced
Role: Data Engineer, Developer / Engineer, Solution / Systems Architect
Services: Amazon Aurora, Amazon Bedrock, Amazon RDS for PostgreSQL
レポート
会場は広く、多くの方が参加していました。

今回は「Blaize Bazaar(ブレイズバザー)」という架空の e コマースプラットフォームを想定してハンズオンを進めます。

RAG を組み合わせて、固有の商品名や価格を検索できるようにします。
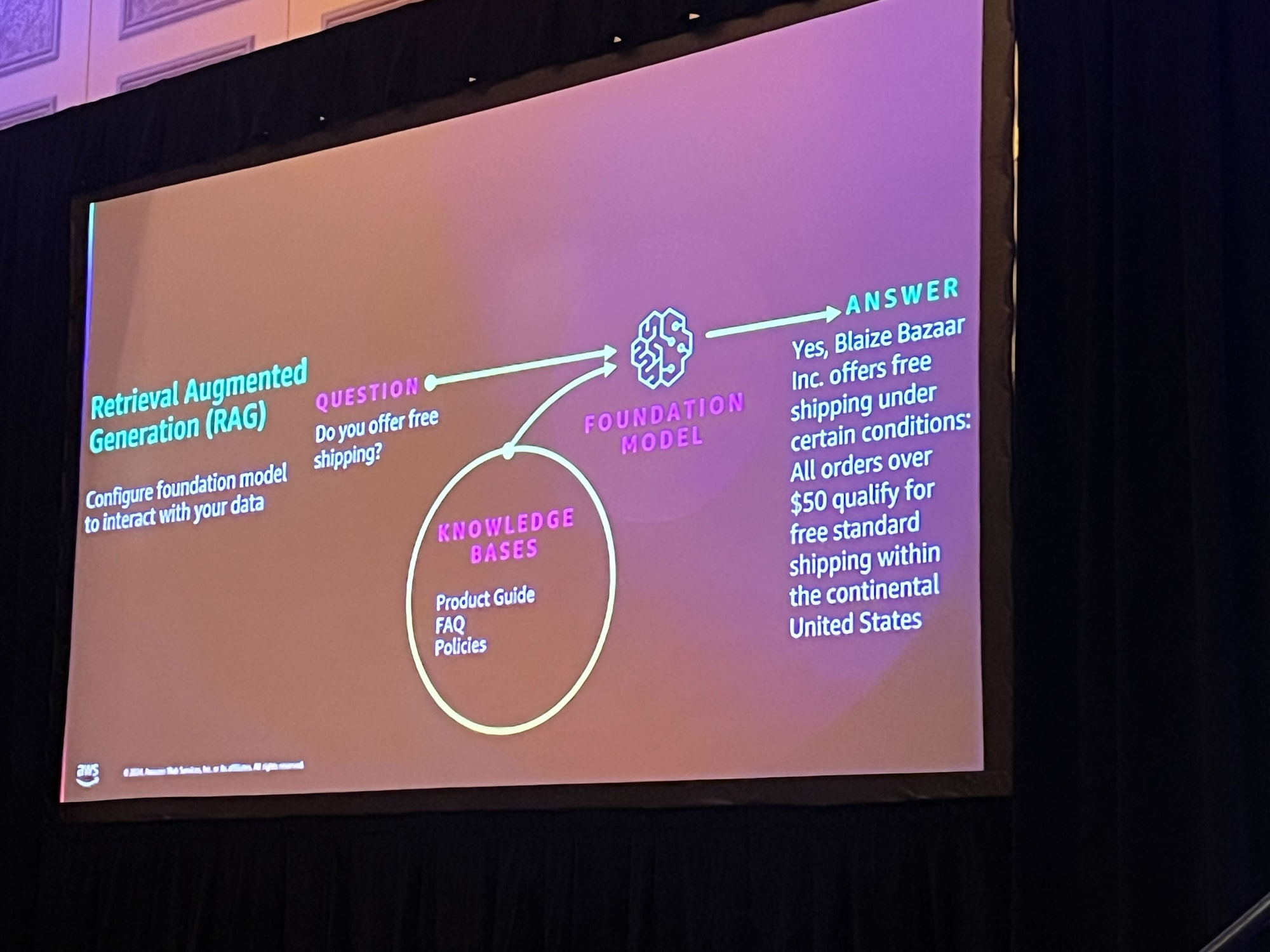

ハンズオン内で使用する pgvector の説明です。
pgvector は、PostgreSQL でベクトル検索を可能にするための拡張機能です。

ワークショップのリンクが共有され、それに沿ってもくもくとハンズオンを進めていきます。
本ハンズオンで使用するプログラムコードは以下で公開されています。
Lab 1
Lab 1 では Aurora PostgreSQL と生成 AI を組み合わせたセマンティック商品検索機能を実装します。

- 商品カタログ(商品名、説明、価格、在庫情報など)のデータから商品説明を抽出
- Amazon Aurora PostgreSQLを ベクトルデータベース として設定し、エンベディングデータを保存
エンベディングとは、文字や画像、音声などのデータを数値ベクトルに変換する技術です。以下のブログの解説が分かりやすいので参考にしてください。
- SageMaker Notebooks から Jupyter Notebook を使用して商品説明を処理し、Bedrock で提供されている生成 AI モデル Amazon Titan Text Embeddings V2 を使ってエンベディング(ベクトルを生成)
- 商品説明をエンベディング(ベクトルに変換)できたら Aurora PostgreSQL に保存
- ユーザーが商品検索を行うと、生成 AI モデル(Amazon Titan Embeddings V2)がクエリをベクトルに変換し、Aurora PostgreSQL でセマンティック検索(類似検索)を実行
JupyterLab の画面では、通常の検索とセマンティック検索の両方が試せるようになっていました。
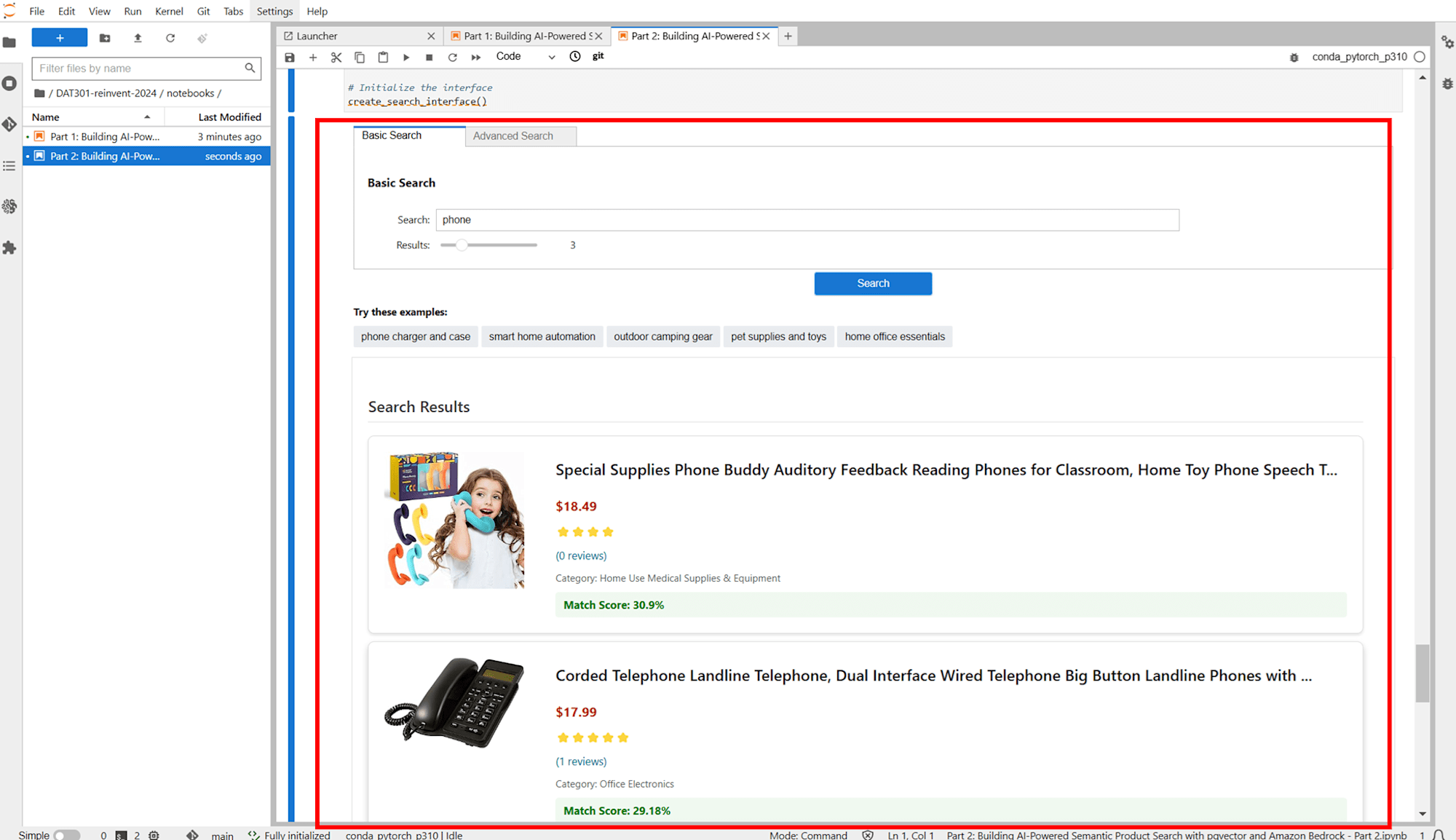
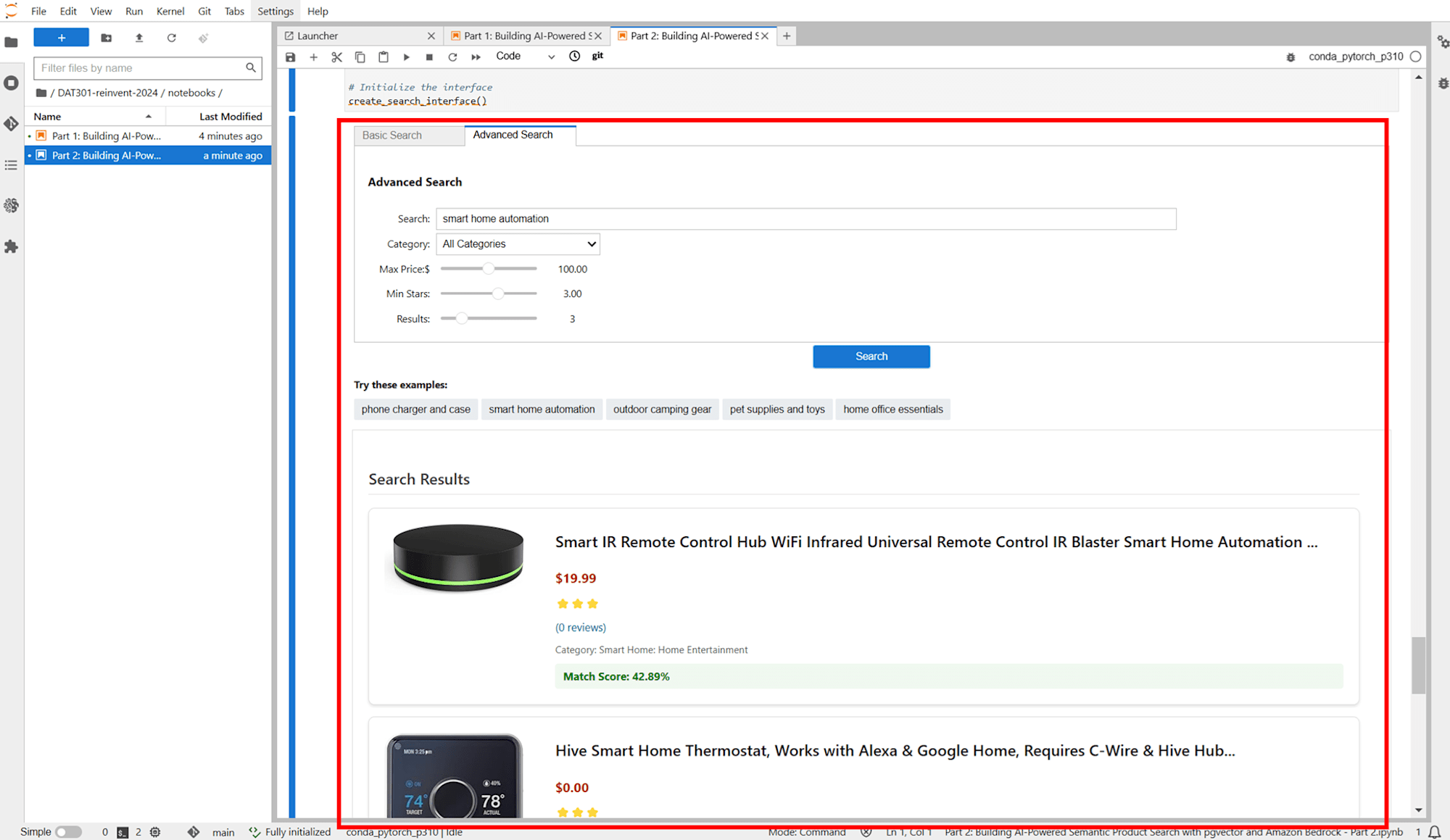
Lab2
Lab 2 では e コマースサイト「Blaize Bazaar」でセマンティック検索や自然言語による問い合わせができるようにしていきます。ユーザーの好みに合わせてレコメンドもしていきます。

製品に関する洞察を得る
Streamlit アプリケーションを起動して e コマースサイトを立ち上げます。かっこいいです。
「Generate AI Insights」ボタンを押下すると、市場動向や売れ筋商品、在庫管理のおすすめなどのインサイトが生成されます。
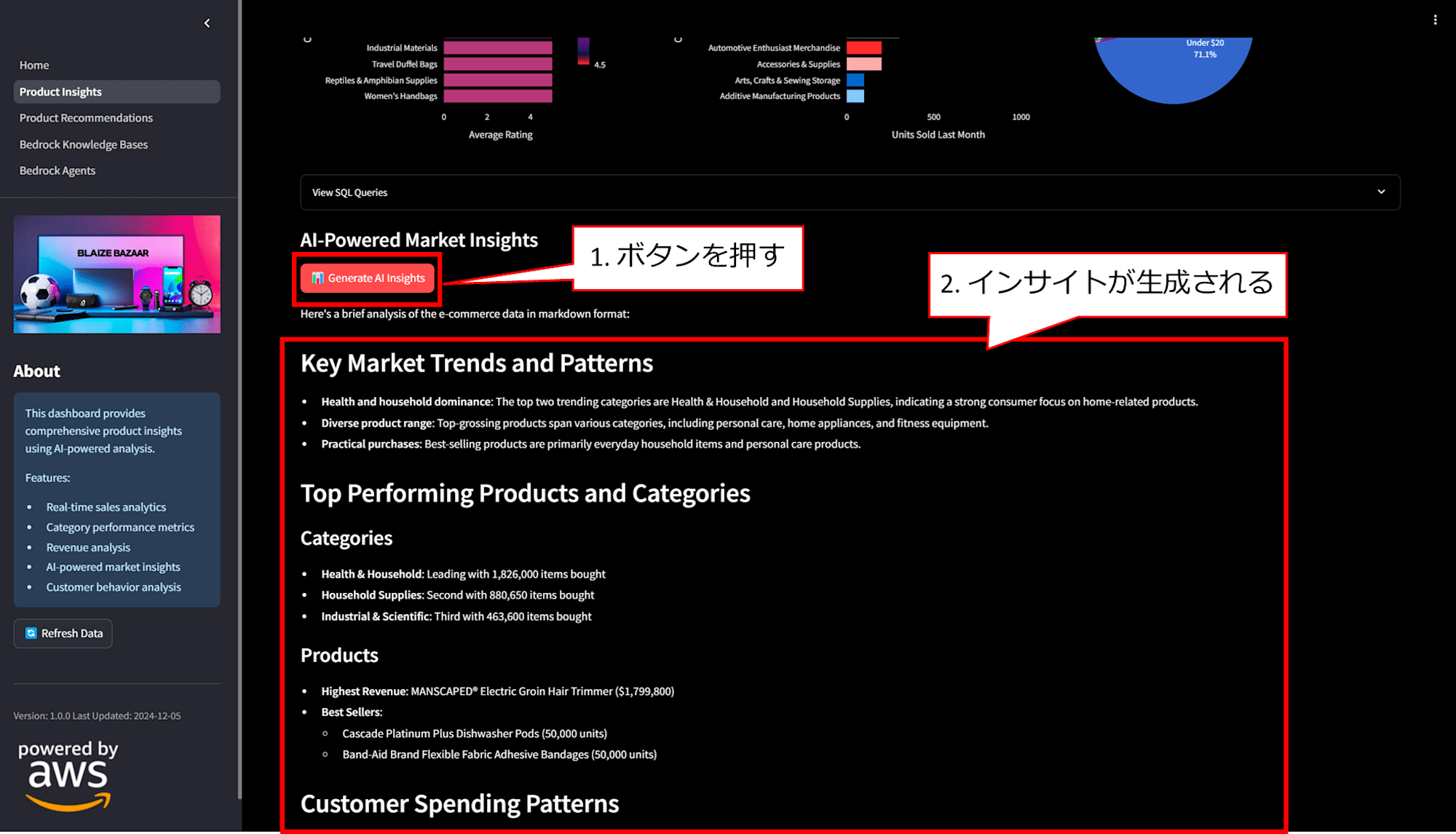
これは 1_Product_Insights.py#L389 の部分でプロンプトし自動生成し、Bedrock の Claude 3.5 Sonnet に問い合わせて生成しています。
製品のおすすめ
興味のあるカテゴリを入力すると、以下のようにお勧めの商品が表示されます。コードは 2_Product_Recommendations.py#L289 の部分で、ここでは PostgreSQL の tsvector を利用したキーワード検索が裏で動いています。(ts_rank の部分)商品の説明をトークン化し、ユーザーのクエリに対して正確な一致を返します。
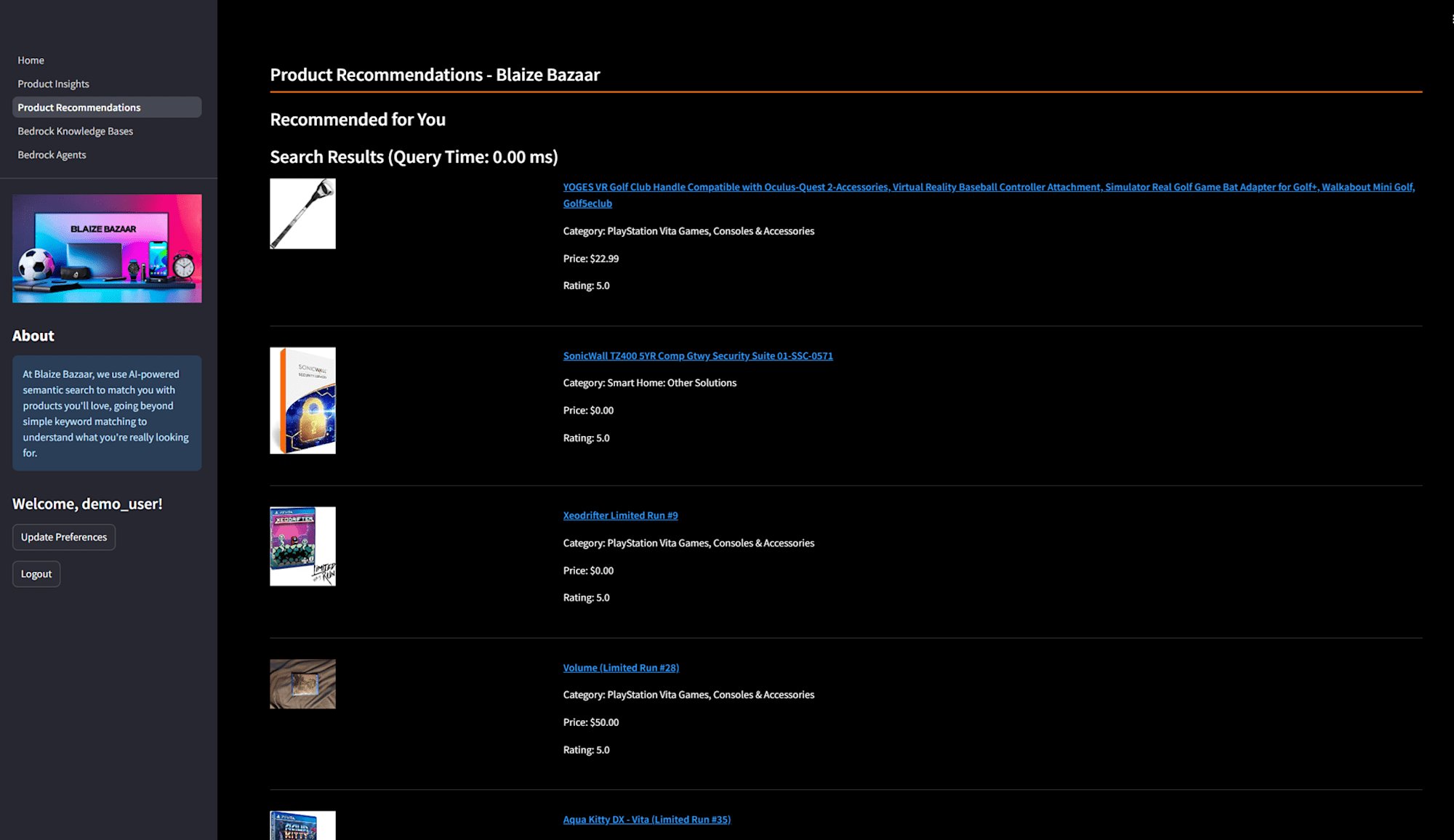
キーワード検索で使用するカテゴリ情報は 2_Product_Recommendations.py#L49 の部分でシンプルさとパフォーマンスを重視し TEXT[] 型を使って管理しています。
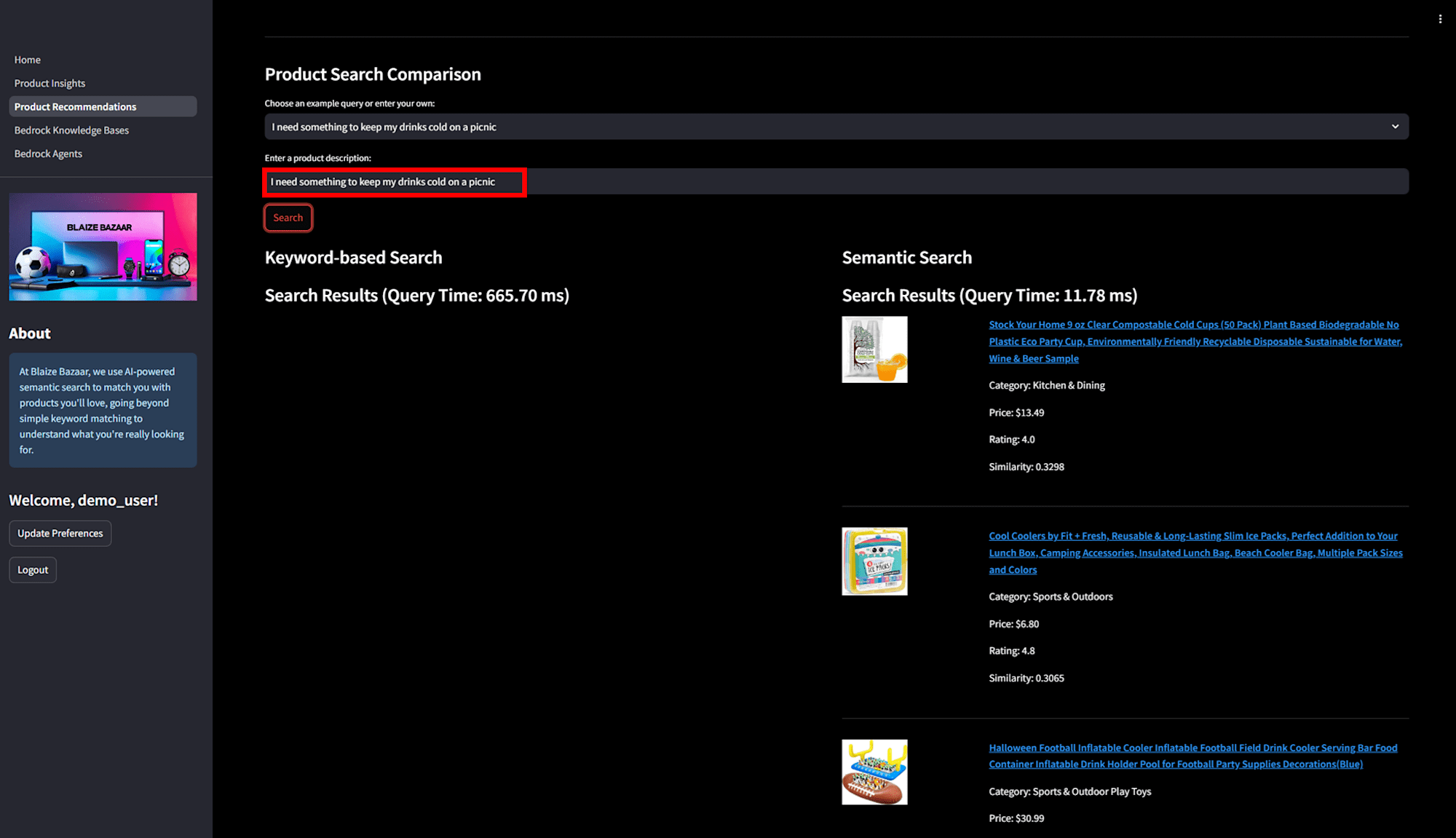
「I need something to keep my drinks cold on a picnic.」のように自然言語で問い合わせる場合は、pgvector を用いたセマンティック検索が動いています。コードは 2_Product_Recommendations.py#L311 の部分で、ベクトル化された埋め込みを比較するため、スペルミスや曖昧な表現でも適切な応答を返すことができます。
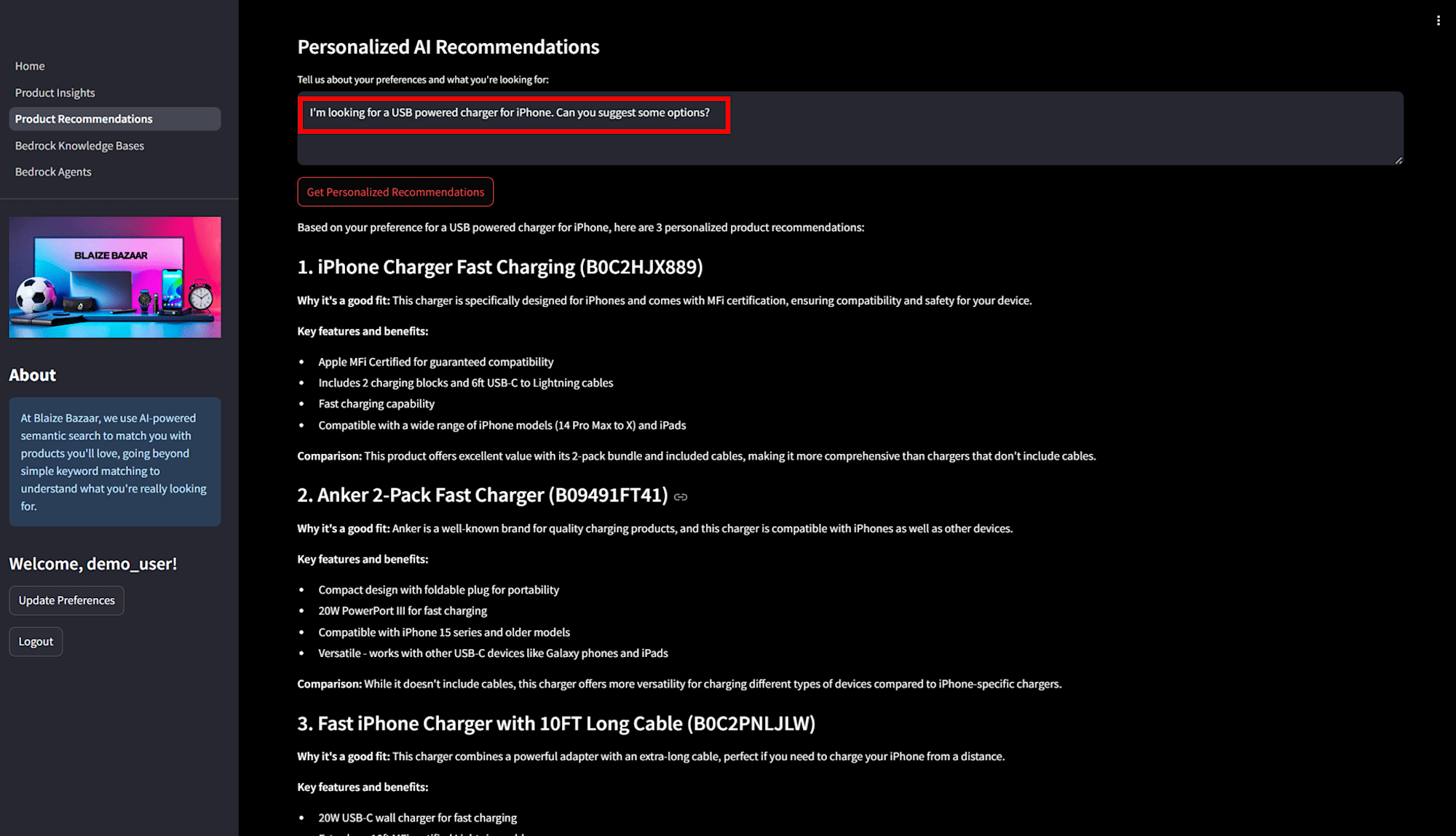
「Personalized AI Recommendations」の部分では、以下のように自然言語で「I'm looking for a USB powered charger for iPhone. Can you suggest some options?」と入力すると、ユーザーの好みに応じた結果が返ってきます。この結果は、ベクトルを用いたセマンティック検索に加え、ユーザーの過去の選好データを考慮したパーソナライズされたレコメンデーションに基づいています。

- 2_Product_Recommendations.py#L336 で Bedrock のエンベディング機能を利用し、商品説明やクエリを高次元ベクトルに変換-
- 商品説明を埋め込みベクトルとして PostgreSQL に保存し、ユーザーのクエリのエンベディングと比較
- コサイン距離(
<=>演算子)を利用し、最も類似度の高い商品を返す
Bedrock Knowledge Bases
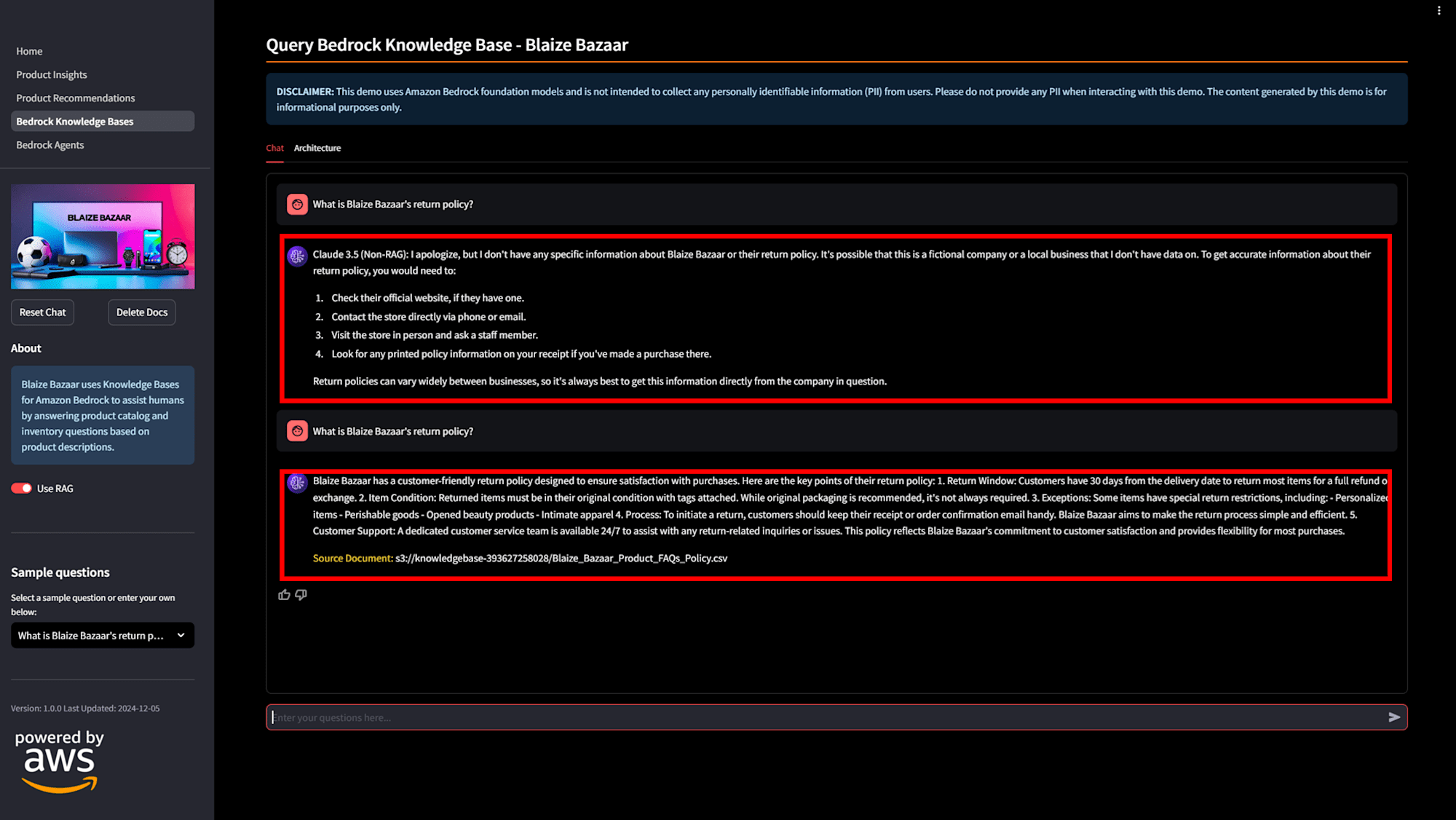
Bedrock ナレッジベースで RAG を実装します。S3 に商品情報などをアップロードし、商品固有の情報も答えられるようにします。コードは 3_Bedrock_Knowledge_Bases.py で、以下の画像のように「RAG」のボタンを ON にすると、Blaize Bazaar の返品ポリシーについて回答が得られるようになります。
Bedrock Agents
Bedrock Agents は、基盤 AI モデル(Foundation Models, FMs)を外部システムと統合し、タスク指向の会話型アプリケーションを簡単に構築できるようにするサービスです。
製品情報を取得するリクエスト(/GetProductsInventory エンドポイント)がエージェントのアクショングループで定義されています。
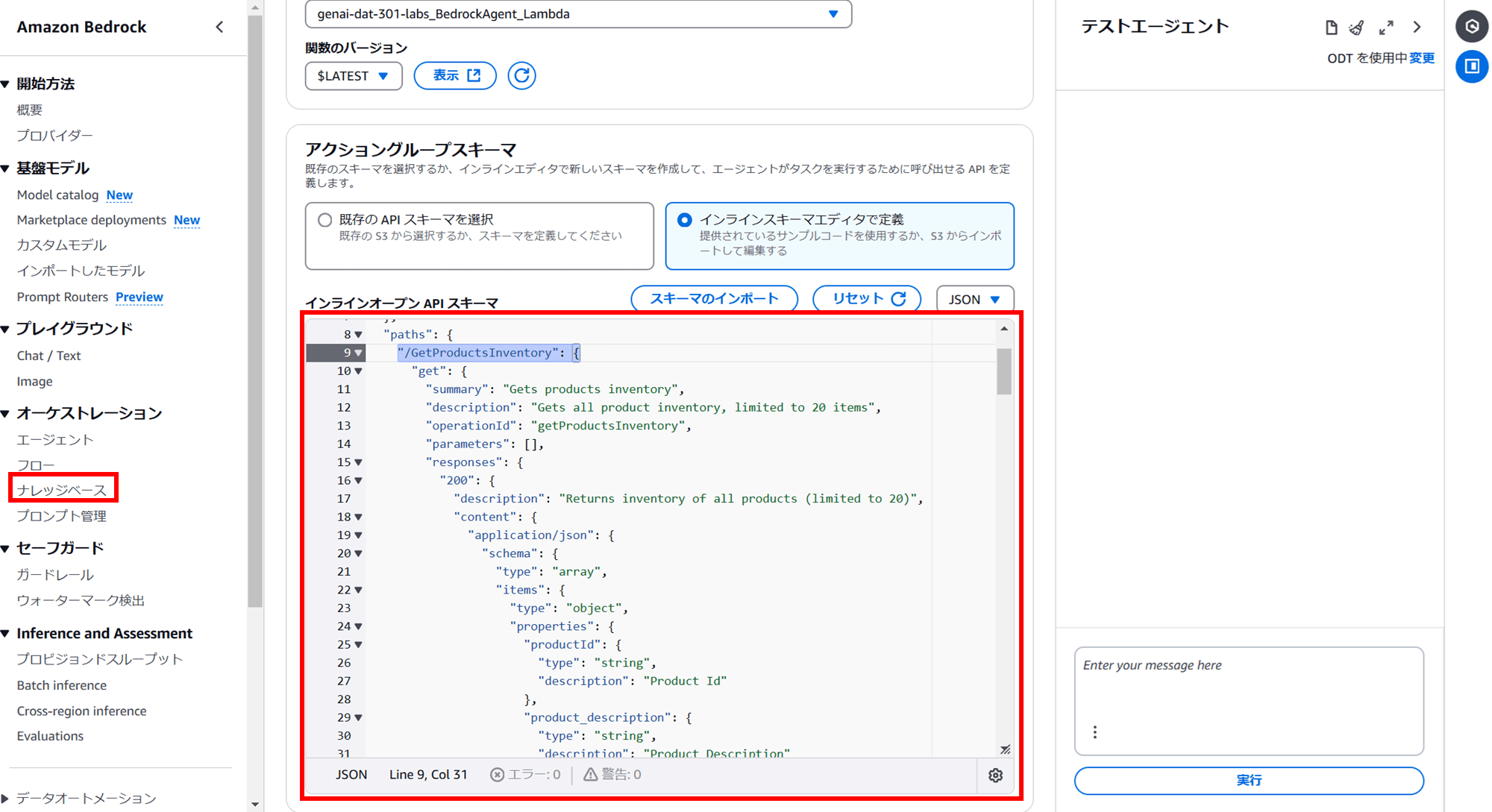
「Can you present Blaize Bazaar's product inventory in a tabular format?」と質問すると、Bedrock Agents が Lambda 関数(get_products_inventory())をキックし、指定条件に一致するデータをデータベースから取得します。取得データを生成 AI モデルで自然言語応答として整形し、求めている表形式の出力を提供します。
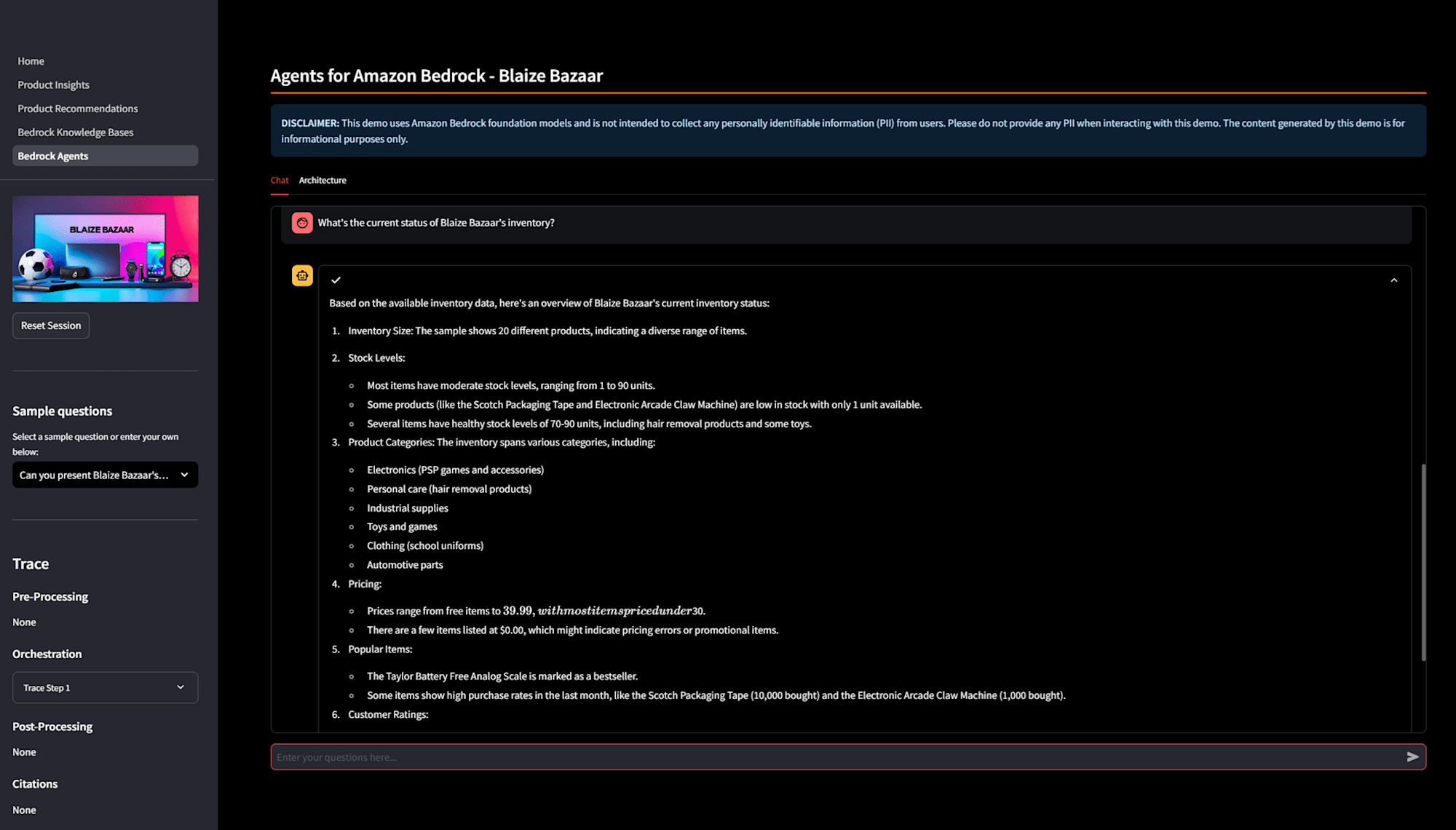
画面左ににトレースログが出ています。
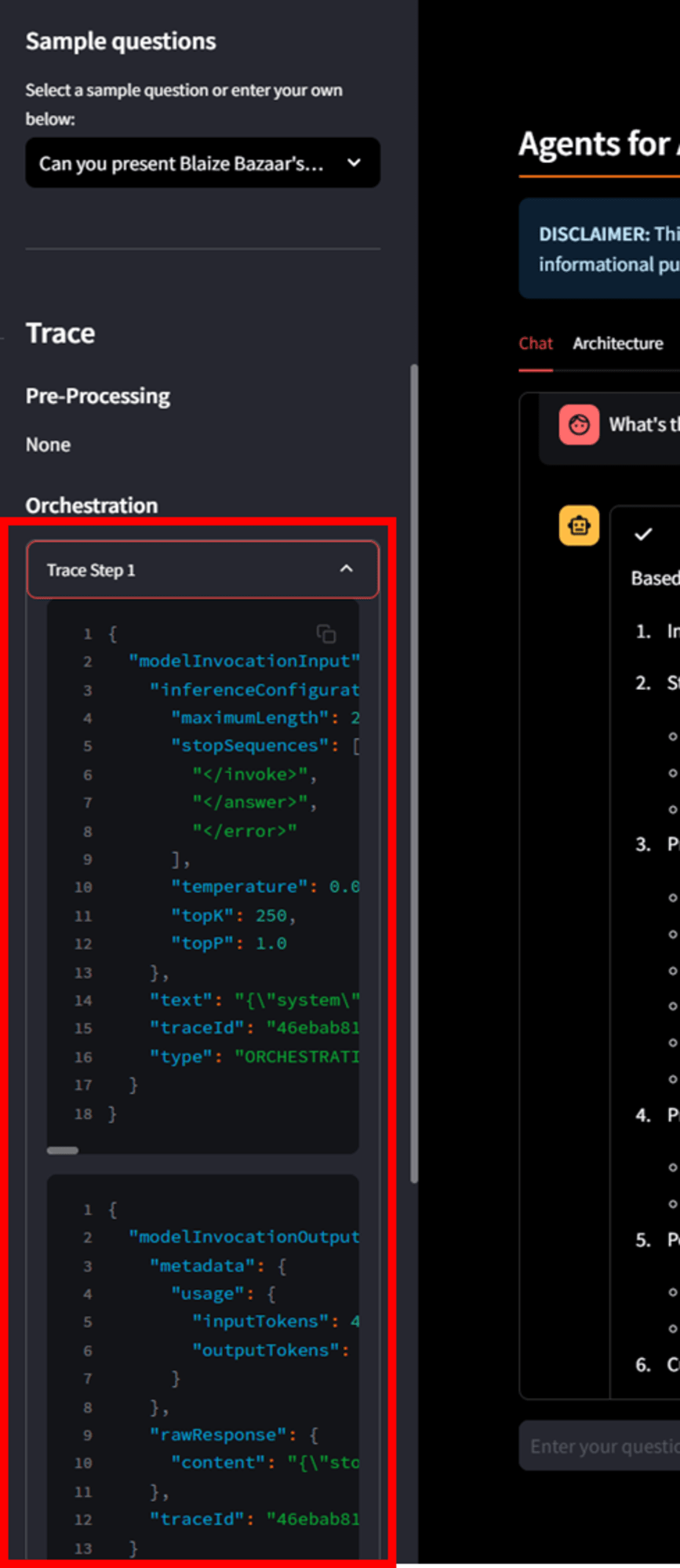
トレースログを確認すると、エージェントが質問に対して Chain of Thought (CoT) 推論とオーケストレーションを組み合わせているプロセスがわかります。
Chain of Thought(CoT)推論は、大規模言語モデル(LLM)が複雑な問題を段階的に解決するための推論方法のことで、簡単に言うと、「問題を一度に解決しようとせず、ステップバイステップで答えを導くプロセス」です。
エージェントが問合せを受けてから、Lambda をキックして、データベースにクエリして、情報を受け取った後表形式に成型して、…という操作を順番にやっているイメージです。賢いですね。
最後に、Aurora PostgreSQL と pgvector を使用した生成 AI のユースケースのワークショップを紹介いただいたので掲載します。これはめちゃくちゃ勉強になりそうです。
終わりに
私は普段インフラ構築ばかりやっていてプログラミングの経験が少ないため、コードを読み解くのがかなり難しかったです。現地で SA の方が声をかけてくれたのですが、「It's difficult for me...」と言いながら最後まで苦戦していました。ラスベガスで心が折れかけています。まだまだセッションレポートを書く予定なので、引き続き頑張ります!







